

ThreadPool
어떤 요청이 들어왔을 때 해당 요청을 처리하기 위해서 쓰레드를 사용하는 가장 심플한 방법은 요청마다 쓰레드를 생성하고 할당하는 것이다
- 쓰레드가 필요한 시점에 생성 요청
- OS가 해당 쓰레드를 위한 메모리 영역 확보 및 할당
- OS Level에서 Native Thread를 위한 메모리 영역을 할당
- 생성된 Native Thread와 User Level Thread 매핑
- Thread's start() 코드 내부에서 JNI를 통해서 Native Code 호출 (with C++)
- 쓰레드 생성 및 Task 실행
- ...
- 쓰레드 사용이 끝나면 OS는 쓰레드를 위해 할당한 메모리 영역을 회수
이러한 과정이 매번 반복되고 결국 이러한 부분들이 쌓이게 되면 불필요한 리소스가 너무나도 많이 낭비가 된다고 볼 수 있다
따라서 Application Performance에도 영향을 주게 된다
이러한 문제점을 해결하기 위해서 ThreadPool이 등장한다
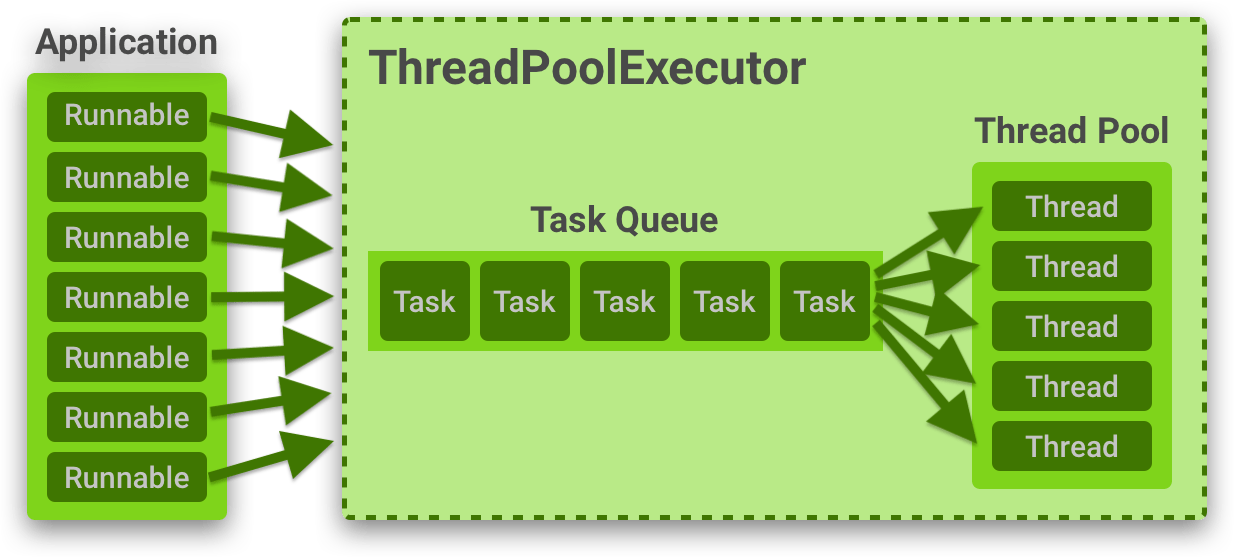
ThreadPool은 필요할때마다 쓰레드를 생성/사용/반납하는게 아니라 미리 정해둔 개수만큼 Pool에 쓰레드를 만들어놓고 요청이 들어오면 만들어 놓은 쓰레드 중 Idle Thread를 할당하는 방식이다
- 미리 정해둔 개수만큼 ThreadPool에 Thread를 만들어놓는다
- 요청이 들어오면 ThreadPool에서 쉬고 있는 Idle Thread 중 하나를 할당한다
- 현재 Idle Thread가 없다면 요청을 Queue에 쌓아놓거나 Pool 상황 + 정책에 따라 거부할 수 있다
- 할당된 Thread가 요청을 다 처리하면 다시 ThreadPool로 돌아간다
이렇게 Thread를 재사용함으로써 Thread 생성 비용 및 여러가지 불필요한 리소스 소모를 줄일 수 있다
하지만 Thread 사용에 대한 Context를 지우지 않고 그대로 ThreadPool에 넣어버린다면 다른 요청에서 미처 지우지 못한 Context를 재사용함으로써 로직에 대한 오류가 발생할 수 있다
- About ThreadLocal
ThreadLocal을 사용할 때 주의점 (remove)
위에서 말했듯이 ThreadLocal을 통해서 Thread별로 특정 자원을 관리하는 경우 관련된 Thread들이 ThreadPool에서 재사용된다면 엉뚱한 Context에서 이전 Thread가 작업하던 내용이 공유될 수 있다
private val store = ThreadLocal<String>()
fun main() {
val executor = Executors.newFixedThreadPool(1)
val clients = listOf("ClientA", "ClientB")
repeat(2) {
executor.submit {
println("## ${clients[it]} ##")
println("첫번째 조회 = ${store.get()}")
store.set("Private Value...")
println("두번째 조회 = ${store.get()}\n")
}
}
}ThreadLocal에 대한 사용이 종료되고 remove하지 않으면 어떤 문제가 발생하는지 코드를 통해서 체험해보자
위의 코드는 Executors.newFixedThreadPool(1)를 통해서 ThreadPool에서 단 하나의 쓰레드만 유지하도록 적용하였다
- repeat간에 동일한 쓰레드를 재사용하기 위한 가정
- repeat1 = ClientA 로직 진행
- repeat2 = ClientB 로직 진행
## ClientA ##
첫번째 조회 = null
두번째 조회 = Private Value...
## ClientB ##
첫번째 조회 = Private Value...
두번째 조회 = Private Value...- ClientB는 분명히 처음 진입하였는데 첫번째 조회에서 ThreadLocal에 ClientA의 작업 내용물이 남아있다
이와 같이 분명히 서로 다른 요청 문맥임에도 불구하고 누군지도 모를 쓰레드가 사용한 내용물이 남아있는 문제가 발생할 수 있다
private val store = ThreadLocal<String>()
fun main() {
val executor = Executors.newFixedThreadPool(1)
val clients = listOf("ClientA", "ClientB")
repeat(2) {
executor.submit {
println("## ${clients[it]} ##")
println("첫번째 조회 = ${store.get()}")
store.set("Private Value...")
println("두번째 조회 = ${store.get()}\n")
store.remove() // ThreadLocal remove
}
}
}## ClientA ##
첫번째 조회 = null
두번째 조회 = Private Value...
## ClientB ##
첫번째 조회 = null
두번째 조회 = Private Value...- 이와 같이 ThreadLocal을 사용하고 나서 반드시 remove해줌으로써 쓰레드 풀을 사용하는 메커니즘에서 다른 쓰레드가 이전 작업물을 공유하는 일이 발생해서는 안된다
ThreadPoolExecutor


ThreadPoolExecutor는 요청으로 들어오는 여러 Task와 ThreadPool을 관리하기 위한 클래스이다
주요 필드
1. corePoolSize

ThreadPool에서 최소한으로 유지되어야 하는 쓰레드 개수
- corePoolSize만큼의 Thread가 모두 일하고 있다면 추가적으로 들어오는 Task들은 workQueue에서 대기한다
2. maximumPoolSize

ThreadPool이 관리할 수 있는 최대 쓰레드 개수
- workQueue가 가득 찬 경우 큐에 쌓인 작업들은 maximumPoolSize까지 동적으로 쓰레드를 생성해서 처리할 수 있다
- corePoolSize + {x..} = maxmiumPoolSize
3. keepAliveTime

Idle 상태의 Thread가 얼마동안 살아있을지에 대한 시간
- corePoolSize로 부족해서 동적으로 maximumPoolSize까지 생성될 수 있는 쓰레드가 생성된 경우 해당 쓰레드가 Idle을 유지할 수 있는 시간
- corePoolSize + {x..} = maxmiumPoolSize
- x.. 개수의 Thread에 대해서 적용되는 시간
4. workQueue → BlockingQueue<Runnable>

corePoolSize만큼의 Thread들이 모두 Task를 진행중일 경우 추가적인 Task들이 대기하는 Queue
- 작업을 처리할 수 있는 Idle Thread가 없는 경우 들어온 작업들은 workQueue에 들어가서 대기
- BlockingQueue에는 null Task 자체가 들어갈 수 없기 때문에 poll()을 통해서 가져온 Task도 null이 될 수 없다
corePoolSize & maximumPoolSize & workQueue간의 관계
fun main() {
val corePoolSize = 10
val maximumPoolSize = 50
val keepAliveTime = 10L
val queue = LinkedBlockingQueue<Runnable>()
val executor = ThreadPoolExecutor(
corePoolSize,
maximumPoolSize,
keepAliveTime,
TimeUnit.SECONDS,
queue
)
val tasks = 60
repeat(tasks) {
executor.submit { Thread.sleep(1000L) }
}
repeat(tasks * 2) {
Thread.sleep(500L)
println("Active = ${executor.activeCount}")
println("Queuing = ${queue.size}")
}
}이 코드는 과연 어떻게 동작할까?
[Case A]
- corePoolSize = 10개의 Thread가 Task 1 ~ 10 진행
- maximumPoolSize = 50이므로 Task 11 ~ 50에 대해서 Thread를 생성해서 진행
- Task 51 ~ 60은 Queue에서 대기
[Case B]
- corePoolSize = 10개의 Thread가 Task 1 ~ 10 진행
- Task 11 ~ 60은 Queue에서 대기
- 앞선 10개의 Task가 끝나면 Queue에서 대기하는 Task들에 대해서 10개씩 corePoolSize만큼의 Thread가 처리
Case A를 선택했다면 틀린 방식을 선택한 것이다
Active = 10
Queuing = 50
Active = 10
Queuing = 40
Active = 10
Queuing = 40
Active = 10
Queuing = 30
Active = 10
Queuing = 30
Active = 10
Queuing = 20
Active = 10
Queuing = 20
Active = 10
Queuing = 10
Active = 10
Queuing = 10
Active = 10
Queuing = 0
Active = 10
Queuing = 0
Active = 0
...- Case B와 같이 동작하는 것을 알 수 있다
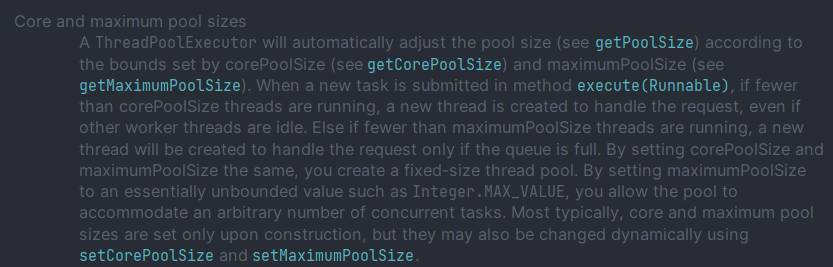
- corePoolSize보다 적은 Thread가 실행 중
- 요청으로 들어온 Runnable Task를 처리할 새로운 Thread를 생성해서 실행
- corePoolSize보다 많은 + maximumPoolSize보다 적은 Thread가 실행 중
- Queue가 가득 찬 경우 = maximumPoolSize가 감당할 수준까지 새로운 Thread를 생성해서 실행
- Queue가 여유로운 경우 = 해당 Task를 Queue에 넣어서 대기시키기
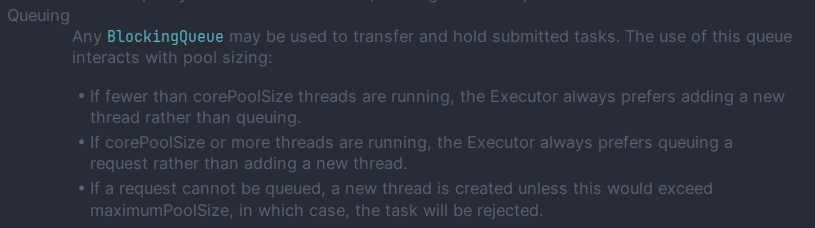
- corePoolSize보다 적은 Thread가 실행 중
- 무조건 새로운 Thread 생성해서 실행
- corePoolSize보다 같거나 많은 Thread가 실행 중
- 무조건 Queuing
- 요청이 Queuing될 수 없는 경우
- maximumPoolSize가 감당할 수준까지 새로운 Thread 생성해서 실행
ThreadPoolExecutor Docs에서 반복적으로 말하고 있는 우선순위 기준은 다음과 같다
1. corePoolSize
2. Queuing
3. maximumPoolSize
그렇기 때문에 위의 케이스에서는 corePoolSize에 해당하는 Thread는 모두 실행중이고 maximumPoolSize & Queue가 모두 여유가 있기 때문에 Queuing을 우선적으로 고려한 Case B가 정답인 것이다
maximumPoolSize & workQueue간의 관계
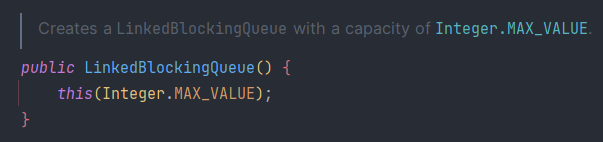
위의 예시코드에서 적용한 BlockingQueue이다
코드를 보면 Queue의 Capacity가 Integer.MAX_VALUE로 적용됨을 확인할 수 있다
다시 생각해보면 위의 코드에서 전체 Task가 60이고 Queue’s Capacity는 Integer.MAX_VALUE인데 maximumPoolSize가 의미가 있을까?
결론은 maximumPoolSize는 사실상 의미가 없는 옵션이라고 생각할 수 있다
- Task가 60개밖에 없는데 Queue’s Capacity는 훨씬 크기 때문에 maximumPoolSize 옵션은 소용이 없는 것
위의 예제 코드에서 Queue's Capacity = 10으로 설정하고 다시 시도해보자
val queue = LinkedBlockingQueue<Runnable>(10)Active = 50
Queuing = 10
Active = 10
Queuing = 0
Active = 10
Queuing = 0
Active = 0
Queuing = 0
...이제서야 maximumPoolSize 옵션이 의미있게 적용됨을 확인할 수 있다
| 설명 | Active & Queuing | |
| Task 1 ~ 10 | corePoolSize = 10이므로 Task 1 ~ 10은 해당 쓰레드에 바로 할당 | Active = 10 Queuing = 0 |
| Task 11 ~ 20 | corePoolSize만큼의 Thread가 모두 실행 중 → Queue에 들어가서 대기 |
Active = 10 Queuing = 10 |
| Task 21 ~ 30 | corePoolSize만큼의 Thread가 모두 실행 중이고 Queue도 가득 찼기 찼음 → maximumPoolSize에 의해서 동적으로 새로운 Thread가 생성되어서 실행 |
Active = 20 (maximumPoolSize 20/50) Queuing = 10 |
| Task 31 ~ 40 | corePoolSize만큼의 Thread가 모두 실행 중이고 Queue도 가득 찼기 찼음 → maximumPoolSize에 의해서 동적으로 새로운 Thread가 생성되어서 실행 |
Active = 30 (maximumPoolSize 30/50) Queuing = 10 |
| Task 41 ~ 50 | corePoolSize만큼의 Thread가 모두 실행 중이고 Queue도 가득 찼기 찼음 → maximumPoolSize에 의해서 동적으로 새로운 Thread가 생성되어서 실행 |
Active = 40 (maximumPoolSize 40/50) Queuing = 10 |
| Task 51 ~ 60 | corePoolSize만큼의 Thread가 모두 실행 중이고 Queue도 가득 찼기 찼음 → maximumPoolSize에 의해서 동적으로 새로운 Thread가 생성되어서 실행 |
Active = 50 (maximumPoolSize 50/50) Queuing = 10 |
| ... | ||
| Task 11 ~ 20 | Thread가 여유로운 시점에 Queue에서 대기하고 있는 10개의 Task를 실행 | Active = 10 Queuing = 10 |
RejectedExecutionHandler
또 다른 상황을 고려해보자
- Queue 가득 참
- maximumPoolSize만큼의 Thread 모두 실행 중
이 상황에서 추가적인 Task가 투입되면 어떤 일이 발생할까?
이 경우의 동작 방식은 RejectedExecutionHandler에 따라 달라진다
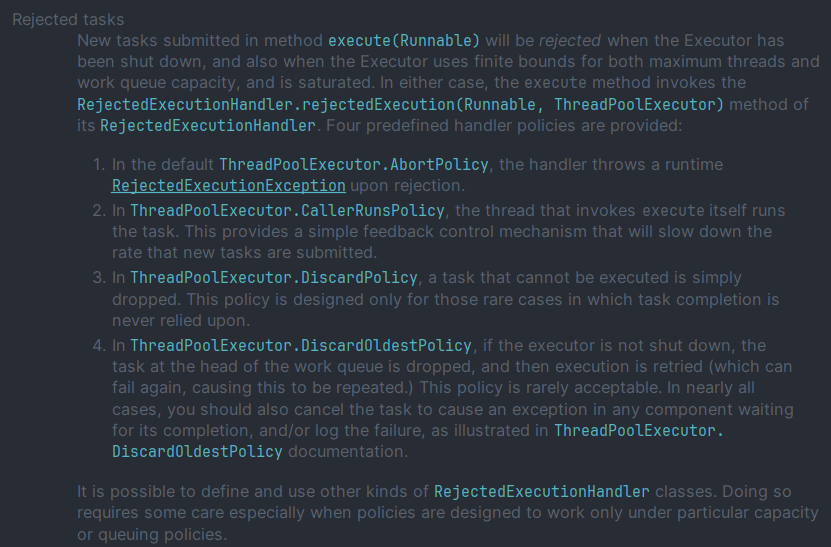
1. AbortPolicy (Default)
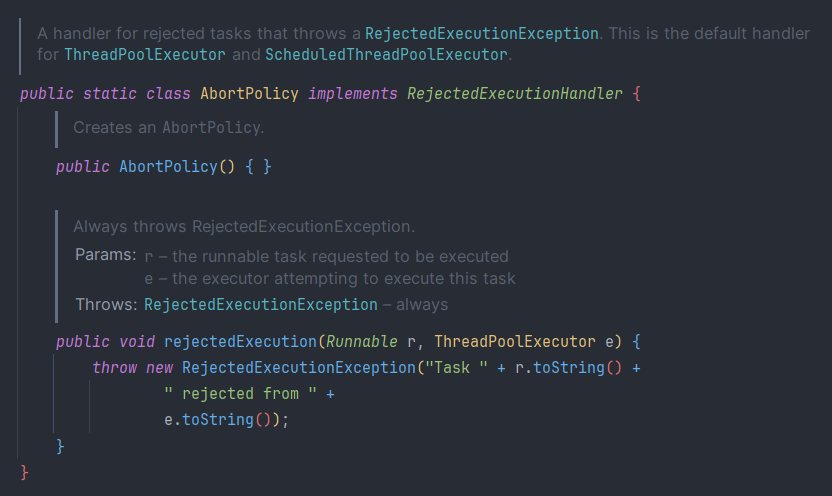
- 더이상 Task를 처리할 수 없는데 추가적인 Task가 들어오는 경우 RejectedExecutionException를 발생시키는 정책
executor.rejectedExecutionHandler = ThreadPoolExecutor.AbortPolicy()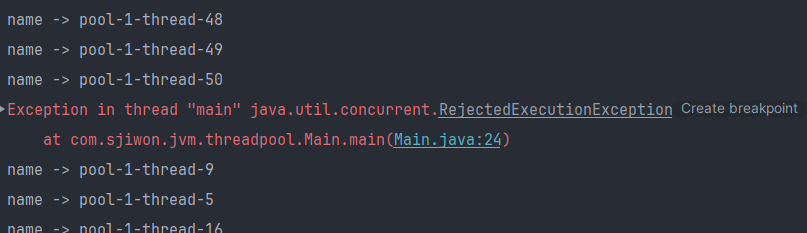
2. CallerRunsPolicy
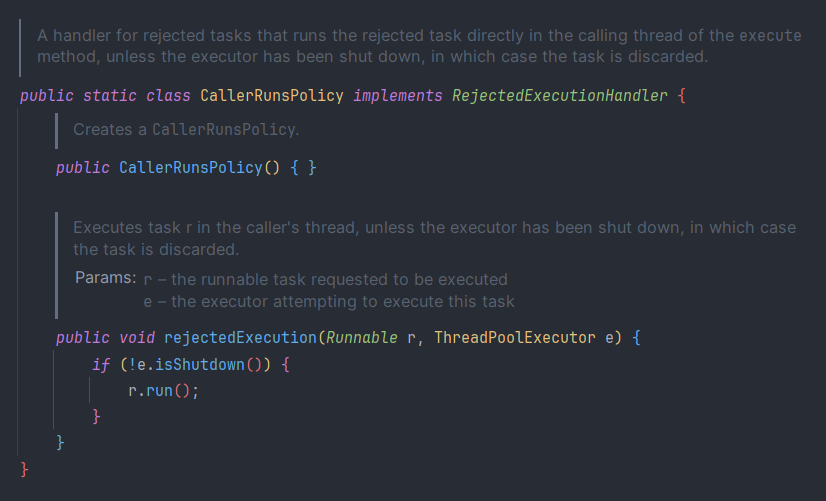
- Task를 execute한 Thread에서 처리되지 못한 Task까지 맡아서 실행하는 정책
executor.rejectedExecutionHandler = ThreadPoolExecutor.CallerRunsPolicy()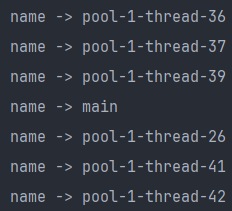
3. DiscardPolicy

- 예외를 발생시키지도 않고 처리하지도 않고 그냥 무시하는 정책
executor.rejectedExecutionHandler = ThreadPoolExecutor.DiscardPolicy()
4. DiscardOldestPolicy
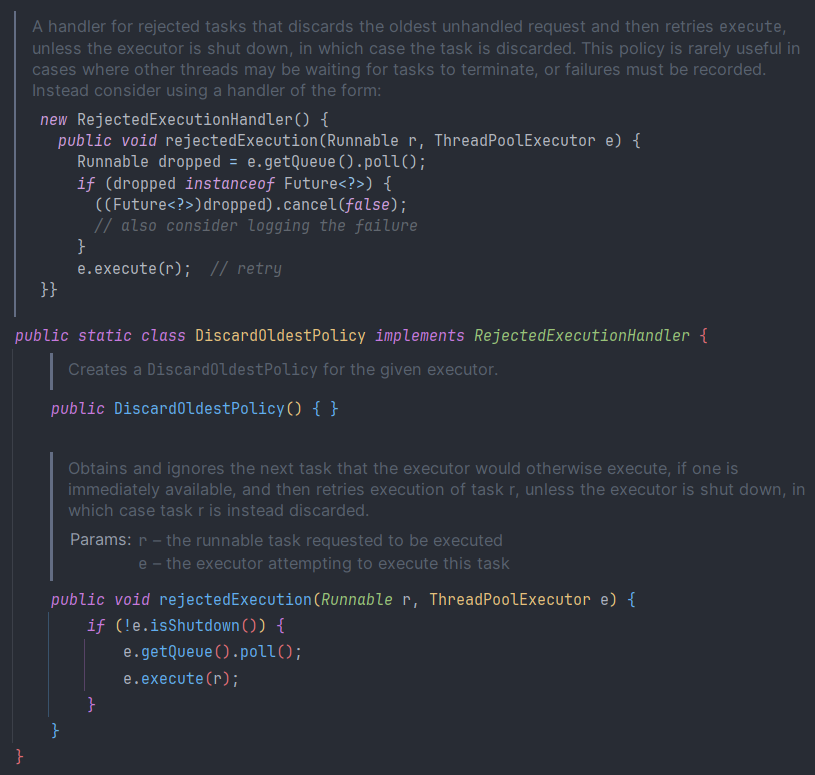
- 처리되지 않은 가장 오래된 Task를 제거하고 현재 Task를 시도해보는 정책
executor.rejectedExecutionHandler = ThreadPoolExecutor.DiscardOldestPolicy()
ScheduledExecutorService
지정된 시간 이후에 실행 or 주기적으로 실행하도록 Task Command를 관리하는 ExecutorService
- delay가 0이거나 음수일 경우 즉시 실행으로 간주
schedule
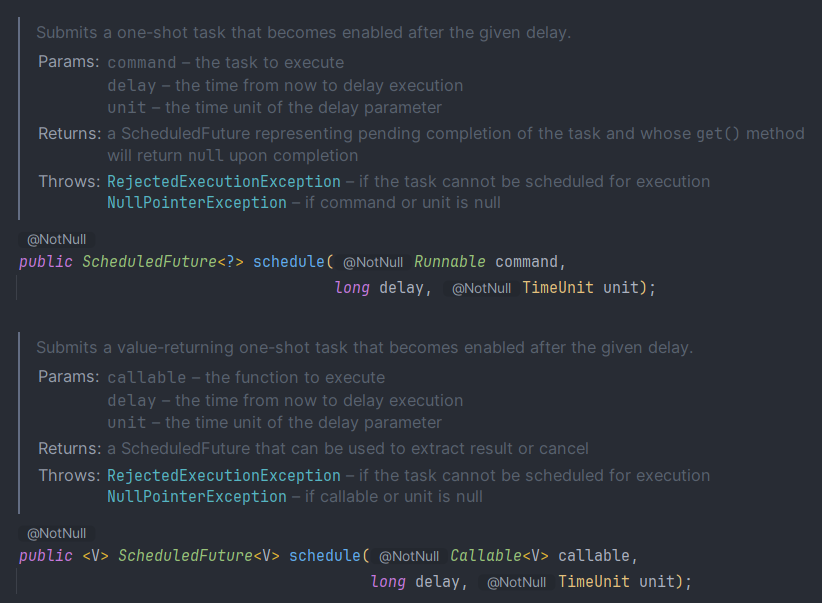
주어진 Delay 후 단 1번의 실행만을 보장하는 스케줄링 Task
val executor = ScheduledThreadPoolExecutor(5)
println("=== Start = ${LocalDateTime.now()} ===")
executor.schedule(
{
println("Thread = ${Thread.currentThread().name}")
println("-> Time = ${LocalDateTime.now()}")
},
2,
TimeUnit.SECONDS
)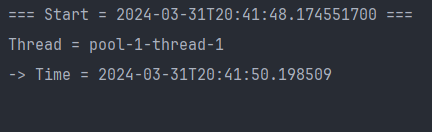
- 주어진 Delay(2초) 후 정확히 1번만 실행
scheduleAtFixedRate
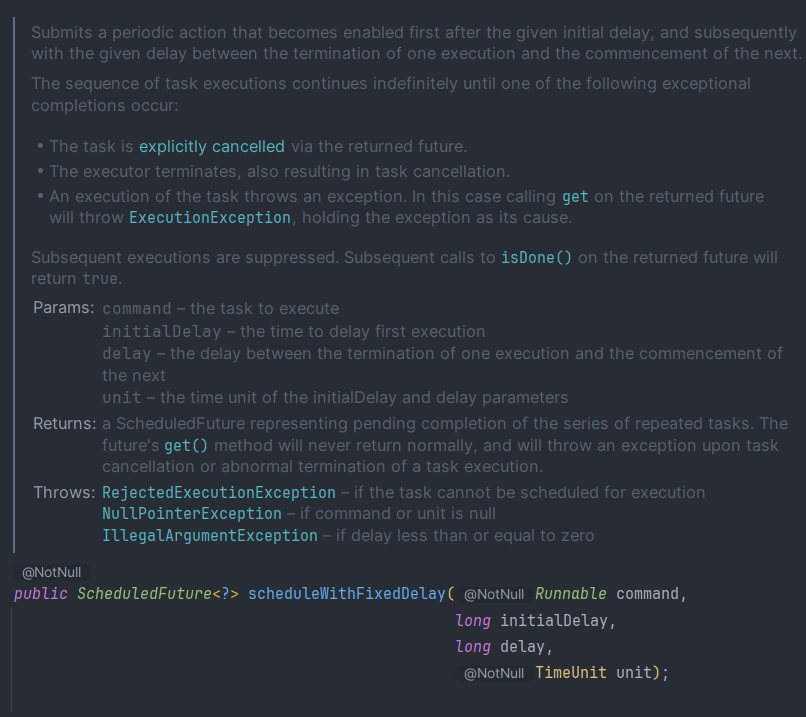
- 처음 실행 = initialDelay가 지나고 실행
- 그 다음 실행 = Delay 간격으로 실행
val executor = ScheduledThreadPoolExecutor(5)
println("=== Start = ${LocalDateTime.now()} ===")
executor.scheduleAtFixedRate(
{
Thread.sleep(1000L)
println("Thread = ${Thread.currentThread().name}")
println("-> Time = ${LocalDateTime.now()}")
},
3,
2,
TimeUnit.SECONDS
)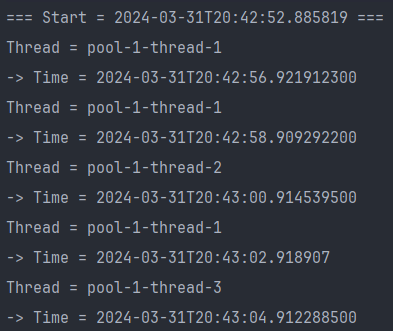
- 처음 실행 = initialDelay(3초) + Thread.sleep(1000) = 4초 후
- 그 다음 실행 = Delay(2초) 간격
scheduleWithFixedDelay
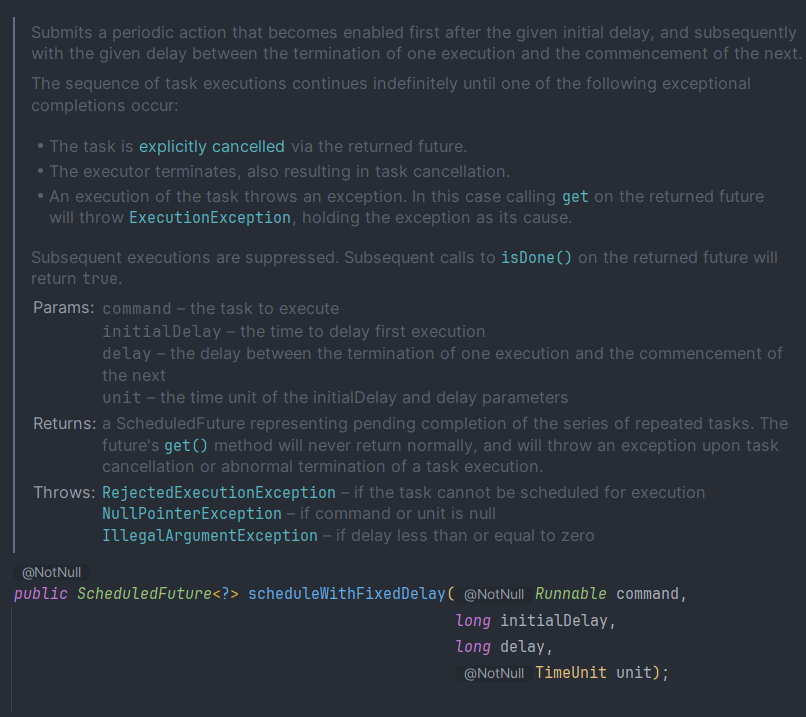
- 처음 실행 = initialDelay가 지나고 실행
- 그 다음 실행 = 이전 Command 종료 + Delay가 지나고 실행
val executor = ScheduledThreadPoolExecutor(5)
println("=== Start = ${LocalDateTime.now()} ===")
executor.scheduleWithFixedDelay(
{
Thread.sleep(1000L)
println("Thread = ${Thread.currentThread().name}")
println("-> Time = ${LocalDateTime.now()}")
},
3,
2,
TimeUnit.SECONDS
)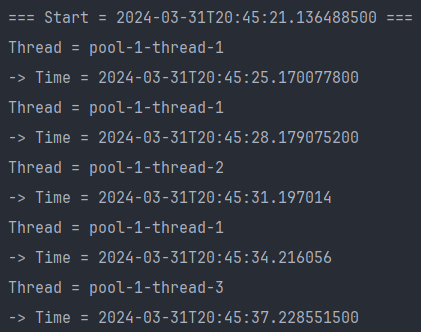
- 처음 실행 = initialDelay(3초) + Thread.sleep(1000) = 4초 후
- 그 다음 실행 = 이전 실행 + Delay(2초) 간격으로 실행
- 이전 실행 = Thread.sleep(1000) + sout