

개요
GitHub - sjiwon/study-with-me-be: 여기서 구해볼래? Backend Repository (Refactoring)
여기서 구해볼래? Backend Repository (Refactoring). Contribute to sjiwon/study-with-me-be development by creating an account on GitHub.
github.com
본 프로젝트 - Study With Me의 메인 페이지에서 가장 많이 조회가 될 거라고 예상되는 스터디 조회에 대한 부하 테스트를 진행하고 여러가지 튜닝을 해보려고 한다
스터디 조회에는 총 3가지 조건이 존재한다
- 등록날짜
- 좋아요 개수
- 리뷰 개수
개선에 앞서
트래픽?
트래픽이 많다? 대규모 트래픽이다?의 정의가 뭘까?
1000TPS? 2000TPS?
개인적으로 생각하는 트래픽이 많다 - 대규모 트래픽이다의 정의는 현재 시스템이 감당할 수 없을 정도의 규모면 대규모 트래픽이라고 생각한다
트래픽이 많이 몰리는 상황에서는 다음과 같은 문제가 발생할 수 있다
- 서버의 처리속도가 느려진다
- 리소스 부족으로 인해 응답에 실패하는 경우가 잦아진다
- 사용자 경험이 나빠진다
- …
통계 결과에 따라 사이트 로딩이 길어지면 길어질수록 사용자는 이탈하기 쉽다
→ 1초 이상 = 약 7%의 사용자가 이탈
→ 3초 이상 = 약 40%의 사용자가 이탈
...
- 이러한 문제점들을 성능 테스트를 통해서 미리 파악하고 병목 지점을 개선함으로써 사용자에게 좋은 경험을 제공해야 한다
테스트를 진행할 더미 데이터의 규모는 다음과 같다
[
{
"member": 1_000_000,
"member_interest": 2_500_756,
"member_review": 1_001_214,
"study": 1_000_000,
"study_hashtag": 2_310_980,
"study_participant": 9_000_000,
"study_notice": 1_000_000,
"study_notice_comment": 1_000_000,
"study_weekly": 1_000_000,
"study_weekly_attachment": 1_000_000,
"study_weekly_submit": 5_000_000,
"study_attendance": 5_000_000,
"study_review": 1_000_342,
"favorite": 2_531_761
}
]
VUser 파악
테스트를 진행하기 앞서 VUser를 파악해보자
- 본 프로젝트와 비슷한 스터디 모집 기능을 제공하는 인프런을 기준으로 파악
MAU = 약 1.3M
DAU = 43333
UserPerHour = 1805
UserPerSecond = 0.5xxx
>> 초당 약 0.5명의 사용자가 이용
여기서 Study With Me 서비스가 인기가 많아져서 초당 100명의 사용자가 이용한다고 가정하고 부하 테스트를 진행해보자
테스트 진행

- 등록날짜 기준 = /api/studies?page=0&sort=date&category=1
- 좋아요 기준 = /api/studies?page=0&sort=favorite&category=1
- 리뷰 개수 기준 = /api/studies?page=0&sort=review&category=1
EC2, RDS 스펙은 아래와 같다
- EC2 = t3.medium (2 vCPU + 4 GiB RAM)
- RDS = db.t3.small (2 vCPU + 2 GiB RAM)
- ThreadPool, HikariCP 설정은 모두 기본값



- 등록날짜도 좋은 성능을 보이지는 못하고 있지만 좋아요 횟수 & 리뷰 개수 기준 조회는 심각한 성능을 보이고 있다

CannotCreateTransactionException


에러 로그를 보니 좋아요 횟수 & 리뷰 개수 기준 조회에서 굉장히 많은 CannotCreateTransactionException이 발생한 것을 확인할 수 있다
이 에러가 발생한 이유는 간단하다
- Connection이 모자라서 Transaction을 시작하지 못함

- 이 결과를 보고 Transaction 범위를 너무 넓게 잡아서 Connection을 낭비하고 있는거 아니냐라는 추측을 할 수 있다
- 현재 조회 쿼리의 경우 Transaction Scope를 query가 날라가는 시점에만 적용 (read-only fetch)하기 때문에 Transaction 범위가 문제되지는 않는다
그러면 성공한 조회도 분석해보자

- 좋아요 횟수 & 리뷰 개수 기준은 그냥 쿼리 자체가 문제

- 등록날짜 기준 쿼리의 경우 쿼리 자체의 문제는 아니고 Connection을 얻는 과정이 오래 걸림에 따라 전체적인 TPS가 낮게 도출됨을 확인하였다
쿼리 분석
각 조회별로 나가는 쿼리는 다음과 같다
| 등록 날짜 | 좋아요 개수 & 리뷰 개 |
| 1. 페이징 처리된 스터디 DTO 쿼리 1개 2. 스터디별 해시태그 쿼리 1개 3. 스터디별 좋아요 마킹 사용자 ID 쿼리 1개 |
1. 페이징 처리된 스터디 ID 쿼리 1개 2. 스터디 ID 기준 스터디 DTO 쿼리 1개 3. 스터디별 해시태그 쿼리 1개 4. 스터디별 좋아요 마킹 사용자 ID 쿼리 1개 |
- 스터디별 해시태그, 좋아요 마킹 쿼리의 경우 IN 쿼리를 통해서 스터디 케이스별로 나가지 않고 1건만 쿼리가 나가도록 최적화한 상태
좋아요 횟수 & 리뷰 개수에서 문제가 되는 Query[1]을 분석해보자
-- 좋아요 횟수 Query[1]
SELECT s1_0.id
FROM study s1_0
LEFT JOIN favorite f1_0 ON f1_0.study_id = s1_0.id
WHERE s1_0.category = 'LANGUAGE' AND s1_0.is_terminated = FALSE
GROUP BY s1_0.id
ORDER BY count(f1_0.id) DESC, s1_0.id DESC
LIMIT 0, 8;
+--+-----------+-----+----------+----+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------------------+-------+---------------------+------+--------+--------------------------------------------+
|id|select_type|table|partitions|type|possible_keys |key |key_len|ref |rows |filtered|Extra |
+--+-----------+-----+----------+----+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------------------+-------+---------------------+------+--------+--------------------------------------------+
|1 |SIMPLE |s1_0 |null |ref |PRIMARY,name,fk_study_host_id_from_member,idx_study_category_is_terminated,idx_study_study_type_category_is_terminated,idx_study_province_city_category_is_terminated,idx_study_province_city_study_type_category_is_terminated|idx_study_category_is_terminated|83 |const,const |298192|100 |Using index; Using temporary; Using filesort|
|1 |SIMPLE |f1_0 |null |ref |fk_favorite_study_id_from_study |fk_favorite_study_id_from_study |8 |study_with_me.s1_0.id|2 |100 |Using index |
+--+-----------+-----+----------+----+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------------------+-------+---------------------+------+--------+--------------------------------------------+
-> Limit: 8 row(s) (actual time=1031..1031 rows=8 loops=1)
-> Sort: count(f1_0.id) DESC, s1_0.id DESC, limit input to 8 row(s) per chunk (actual time=1031..1031 rows=8 loops=1)
-> Stream results (cost=273570 rows=830309) (actual time=0.227..1001 rows=166932 loops=1)
-> Group aggregate: count(f1_0.id) (cost=273570 rows=830309) (actual time=0.225..962 rows=166932 loops=1)
-> Nested loop left join (cost=190539 rows=830309) (actual time=0.214..891 rows=436343 loops=1)
-> Covering index lookup on s1_0 using idx_study_category_is_terminated (category='LANGUAGE', is_terminated=false) (cost=32701 rows=298192) (actual time=0.199..98.9 rows=166932 loops=1)
-> Covering index lookup on f1_0 using fk_favorite_study_id_from_study (study_id=s1_0.id) (cost=0.251 rows=2.78) (actual time=0.00362..0.00442 rows=2.53 loops=166932)
-- 리뷰 개수 Query[1]
SELECT s1_0.id
FROM study s1_0
LEFT JOIN study_review s2_0 ON s2_0.study_id = s1_0.id
WHERE s1_0.category = 'LANGUAGE' AND s1_0.is_terminated = FALSE
GROUP BY s1_0.id
ORDER BY count(s2_0.id) DESC, s1_0.id DESC
LIMIT 0, 8;
+--+-----------+-----+----------+----+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-----------------------------------+-------+---------------------+------+--------+--------------------------------------------+
|id|select_type|table|partitions|type|possible_keys |key |key_len|ref |rows |filtered|Extra |
+--+-----------+-----+----------+----+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-----------------------------------+-------+---------------------+------+--------+--------------------------------------------+
|1 |SIMPLE |s1_0 |null |ref |PRIMARY,name,fk_study_host_id_from_member,idx_study_category_is_terminated,idx_study_study_type_category_is_terminated,idx_study_province_city_category_is_terminated,idx_study_province_city_study_type_category_is_terminated|idx_study_category_is_terminated |83 |const,const |298192|100 |Using index; Using temporary; Using filesort|
|1 |SIMPLE |s2_0 |null |ref |fk_study_review_study_id_from_study |fk_study_review_study_id_from_study|8 |study_with_me.s1_0.id|1 |100 |Using index |
+--+-----------+-----+----------+----+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+-----------------------------------+-------+---------------------+------+--------+--------------------------------------------+
-> Limit: 8 row(s) (actual time=731..731 rows=8 loops=1)
-> Sort: count(s2_0.id) DESC, s1_0.id DESC, limit input to 8 row(s) per chunk (actual time=731..731 rows=8 loops=1)
-> Stream results (cost=203219 rows=475182) (actual time=0.101..701 rows=166932 loops=1)
-> Group aggregate: count(s2_0.id) (cost=203219 rows=475182) (actual time=0.0991..672 rows=166932 loops=1)
-> Nested loop left join (cost=155701 rows=475182) (actual time=0.0894..624 rows=222531 loops=1)
-> Covering index lookup on s1_0 using idx_study_category_is_terminated (category='LANGUAGE', is_terminated=false) (cost=32701 rows=298192) (actual time=0.0742..77.7 rows=166932 loops=1)
-> Covering index lookup on s2_0 using fk_study_review_study_id_from_study (study_id=s1_0.id) (cost=0.253 rows=1.59) (actual time=0.00267..0.00308 rows=1 loops=166932)- 쿼리 Analyze 결과를 보니 현재 쿼리의 조건절과 조인은 Index를 통해서 원활하게 이루어지고 있다
- 두 쿼리의 실질적인 문제는 using temporary; using filesort;를 통해서 임시 테이블을 생성한 후 파일 정렬 방식을 사용한다는 것이다
쿼리 개선 방향
[스터디 좋아요 등록]
- 스터디에 대한 좋아요 등록 및 취소는 로그인한 사용자 누구든 진행할 수 있다
- 인기 있는 스터디는 이러한 좋아요 등록이 빈번하게 발생할 여지가 있다
[스터디 리뷰 등록]
- 스터디 리뷰 작성은 스터디 졸업을 위한 조건을 만족한 사람이 졸업 후 작성할 수 있다
favoriteCount, reviewCount 반정규화를 통해서 좋아요, 리뷰 등록 시 study's favoriteCount++, reviewCount++를 진행하는 것은 만약 여러 사용자가 동시에 들어올 경우 동시성 문제가 발생할 여지가 있다
- 조인 후 Count Grouping 하는 과정 자체에서 쿼리 비용에 대한 오버헤드가 심한걸로 판단함에 따라 반정규화 진행
따라서 Optimistic Lock을 활용한 Version Control로 count에 대한 정합성을 보장하려고 한다
- 밑에서 볼 수 있겠지만 이 방식은 현재 로직상에서 데드락을 유발
로직 개선 진행
using temporary; using filesort; 실행계획 개선
-- 좋아요 개수 기준
SELECT
s1_0.id,
s1_0.name,
s1_0.description,
s1_0.category,
s1_0.thumbnail,
s1_0.study_type,
s1_0.recruitment_status,
s1_0.capacity,
s1_0.participants,
s1_0.created_at
FROM study s1_0
WHERE s1_0.category = 'LANGUAGE' AND s1_0.is_terminated = FALSE
ORDER BY s1_0.favorite_count DESC, s1_0.id DESC
LIMIT 0, 8;
+--+-----------+-----+----------+----+------------------------------------------------------------------------------------------------------------------------------+-----------------------------------------------+-------+-----------+------+--------+-------------------+
|id|select_type|table|partitions|type|possible_keys |key |key_len|ref |rows |filtered|Extra |
+--+-----------+-----+----------+----+------------------------------------------------------------------------------------------------------------------------------+-----------------------------------------------+-------+-----------+------+--------+-------------------+
|1 |SIMPLE |s1_0 |null |ref |idx_study_category_is_terminated_favorite_count,idx_study_category_is_terminated_review_count,idx_study_category_is_terminated|idx_study_category_is_terminated_favorite_count|83 |const,const|330560|100 |Backward index scan|
+--+-----------+-----+----------+----+------------------------------------------------------------------------------------------------------------------------------+-----------------------------------------------+-------+-----------+------+--------+-------------------+
-> Limit: 8 row(s) (cost=40866 rows=8) (actual time=0.0309..0.0615 rows=8 loops=1)
-> Index lookup on s1_0 using idx_study_category_is_terminated_favorite_count (category='LANGUAGE', is_terminated=false) (reverse) (cost=40866 rows=330560) (actual time=0.0301..0.06 rows=8 loops=1)
-- 리뷰 개수 기준
SELECT
s1_0.id,
s1_0.name,
s1_0.description,
s1_0.category,
s1_0.thumbnail,
s1_0.study_type,
s1_0.recruitment_status,
s1_0.capacity,
s1_0.participants,
s1_0.created_at
FROM study s1_0
WHERE s1_0.category = 'LANGUAGE' AND s1_0.is_terminated = FALSE
ORDER BY s1_0.review_count DESC, s1_0.id DESC
LIMIT 0, 8;
+--+-----------+-----+----------+----+------------------------------------------------------------------------------------------------------------------------------+---------------------------------------------+-------+-----------+------+--------+-------------------+
|id|select_type|table|partitions|type|possible_keys |key |key_len|ref |rows |filtered|Extra |
+--+-----------+-----+----------+----+------------------------------------------------------------------------------------------------------------------------------+---------------------------------------------+-------+-----------+------+--------+-------------------+
|1 |SIMPLE |s1_0 |null |ref |idx_study_category_is_terminated_favorite_count,idx_study_category_is_terminated_review_count,idx_study_category_is_terminated|idx_study_category_is_terminated_review_count|83 |const,const|330560|100 |Backward index scan|
+--+-----------+-----+----------+----+------------------------------------------------------------------------------------------------------------------------------+---------------------------------------------+-------+-----------+------+--------+-------------------+
-> Limit: 8 row(s) (cost=40866 rows=8) (actual time=0.0269..0.0466 rows=8 loops=1)
-> Index lookup on s1_0 using idx_study_category_is_terminated_review_count (category='LANGUAGE', is_terminated=false) (reverse) (cost=40866 rows=330560) (actual time=0.026..0.0451 rows=8 loops=1)- using temporary; using filesort;가 아닌 모두 Index를 활용해서 쿼리를 필터링하고 조회함을 확인할 수 있다
동시성 처리
1. Optimistic Lock → Deadlock 발생
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
@Entity
@Table(name = "study")
public class Study extends BaseEntity<Study> {
...
// Denormalization
@Column(name = "favorite_count", nullable = false)
private int favoriteCount;
@Column(name = "review_count", nullable = false)
private int reviewCount;
@Version
private Long version;
...
}@Target({ElementType.TYPE, ElementType.METHOD})
@Retention(RetentionPolicy.RUNTIME)
public @interface OptimisticLockRetry {
int maxRetry() default -1; // infinite
boolean withInTranction() default false;
}
@Slf4j
@Aspect
@Component
@RequiredArgsConstructor
public class OptimisticLockAop {
private final AopWithTransactional aopWithTransactional;
@Around("@annotation(com.kgu.studywithme.global.lock.OptimisticLockRetry)")
public Object checkAuthUser(final ProceedingJoinPoint joinPoint) {
final MethodSignature signature = (MethodSignature) joinPoint.getSignature();
final Method method = signature.getMethod();
final OptimisticLockRetry optimisticLockRetry = method.getAnnotation(OptimisticLockRetry.class);
int currentRetry = 0;
while (true) {
try {
if (tryMaximum(currentRetry++, optimisticLockRetry, method)) {
throw new RuntimeException("Retry Exception...");
}
if (optimisticLockRetry.withInTranction()) {
return aopWithTransactional.proceed(joinPoint);
}
return joinPoint.proceed();
} catch (final OptimisticLockException e) {
log.info(
"Optimistic Lock Version Miss... -> retry = {}, maxRetry = {}, withInTransaction = {}",
currentRetry,
optimisticLockRetry.maxRetry(),
optimisticLockRetry.withInTranction()
);
try {
Thread.sleep(50);
} catch (final InterruptedException ex) {
throw new RuntimeException(ex);
}
} catch (final StudyWithMeException e) {
throw e;
} catch (final Throwable e) {
throw new RuntimeException(e);
}
}
}
private boolean tryMaximum(final int currentRetry, final OptimisticLockRetry optimisticLockRetry, final Method method) {
if (optimisticLockRetry.maxRetry() != -1 && optimisticLockRetry.maxRetry() == currentRetry) {
log.error("Retry Exception... -> method = {}", method);
return true;
}
return false;
}
}@Service
@RequiredArgsConstructor
public class ManageFavoriteUseCase {
private final StudyRepository studyRepository;
private final MemberRepository memberRepository;
private final FavoriteRepository favoriteRepository;
@OptimisticLockRetry(withInTranction = true)
public Long markLike(final MarkStudyLikeCommand command) {
final Study study = studyRepository.getById(command.studyId());
final Member member = memberRepository.getById(command.memberId());
try {
study.increaseFavoriteCount();
final Favorite favorite = favoriteRepository.save(Favorite.favoriteMarking(member, study));
return favorite.getId();
} catch (final DataIntegrityViolationException e) {
throw StudyWithMeException.type(FavoriteErrorCode.ALREADY_LIKE_MARKED);
}
}
@OptimisticLockRetry(withInTranction = true)
public void cancelLike(final CancelStudyLikeCommand command) {
final Study study = studyRepository.getById(command.studyId());
final Favorite favorite = favoriteRepository.getFavoriteRecord(study.getId(), command.memberId());
study.decreaseFavoriteCount();
favoriteRepository.delete(favorite);
}
}

- Optimistic Lock + Retry를 통해서 시도한 결과는 데드락이 발생하게 되었다
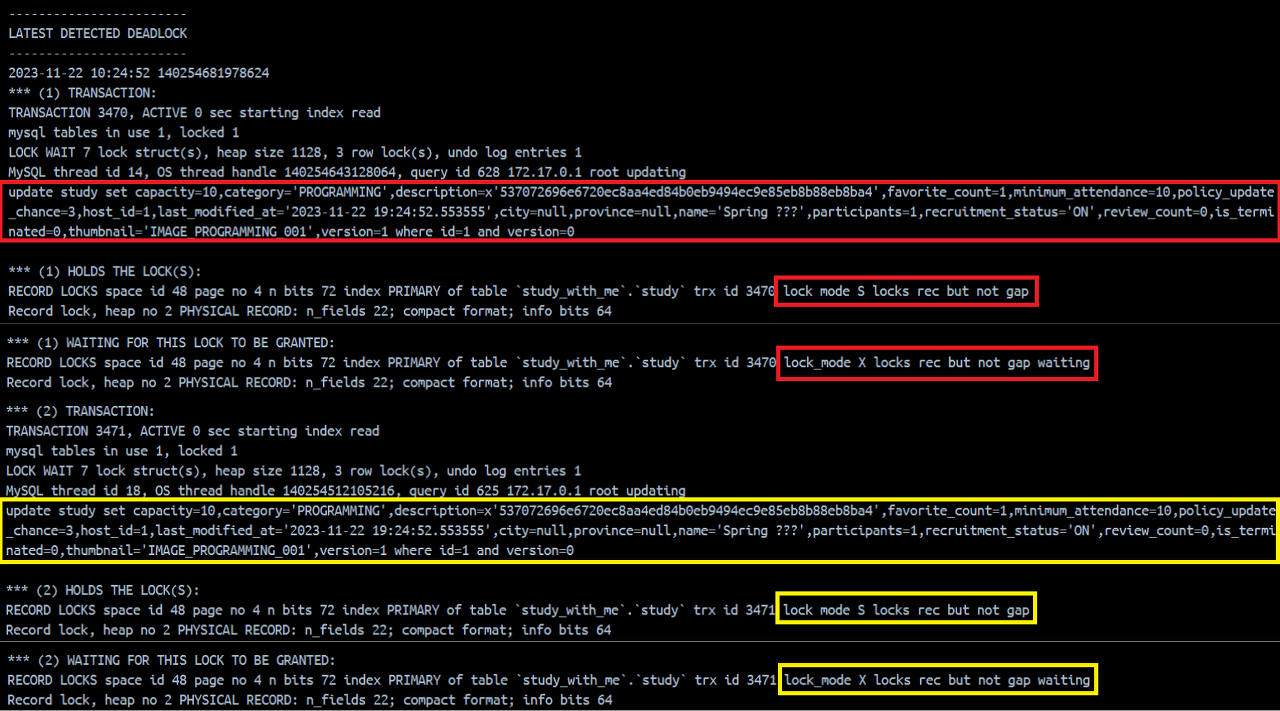
- Favorite Insert 과정에서 X-Lock을 획득하고 외래키인 member, study Record에 S-Lock 전파
- S-Lock이 전파된 상태에서 study update를 진행하려고 X-Lock을 요청
- 공존할 수 없는 S-Lock & X-Lock으로 인해 데드락 발생
2. Direct Update Query
@Service
@RequiredArgsConstructor
public class ManageFavoriteUseCase {
private final StudyRepository studyRepository;
private final MemberRepository memberRepository;
private final FavoriteRepository favoriteRepository;
@StudyWithMeWritableTransactional
public Long markLike(final MarkStudyLikeCommand command) {
final Study study = studyRepository.getById(command.studyId());
final Member member = memberRepository.getById(command.memberId());
try {
studyRepository.increaseFavoriteCount(study.getId());
final Favorite favorite = favoriteRepository.save(Favorite.favoriteMarking(member, study));
return favorite.getId();
} catch (final DataIntegrityViolationException e) {
throw StudyWithMeException.type(FavoriteErrorCode.ALREADY_LIKE_MARKED);
}
}
@StudyWithMeWritableTransactional
public void cancelLike(final CancelStudyLikeCommand command) {
final Study study = studyRepository.getById(command.studyId());
final Favorite favorite = favoriteRepository.getFavoriteRecord(study.getId(), command.memberId());
studyRepository.decreaseFavoriteCount(study.getId());
favoriteRepository.delete(favorite);
}
}- Optimistic Locking이 아니라 직접 Update Query를 날림으로써 정합성을 보장하는 방향으로 개선하였다

반정규화 후 테이블 데이터 정합성 보장 쿼리
UPDATE study s
SET s.favorite_count = (SELECT COUNT(f.id)
FROM favorite f
WHERE f.study_id = s.id),
s.review_count = (SELECT COUNT(r.id)
FROM study_review r
WHERE r.study_id = s.id);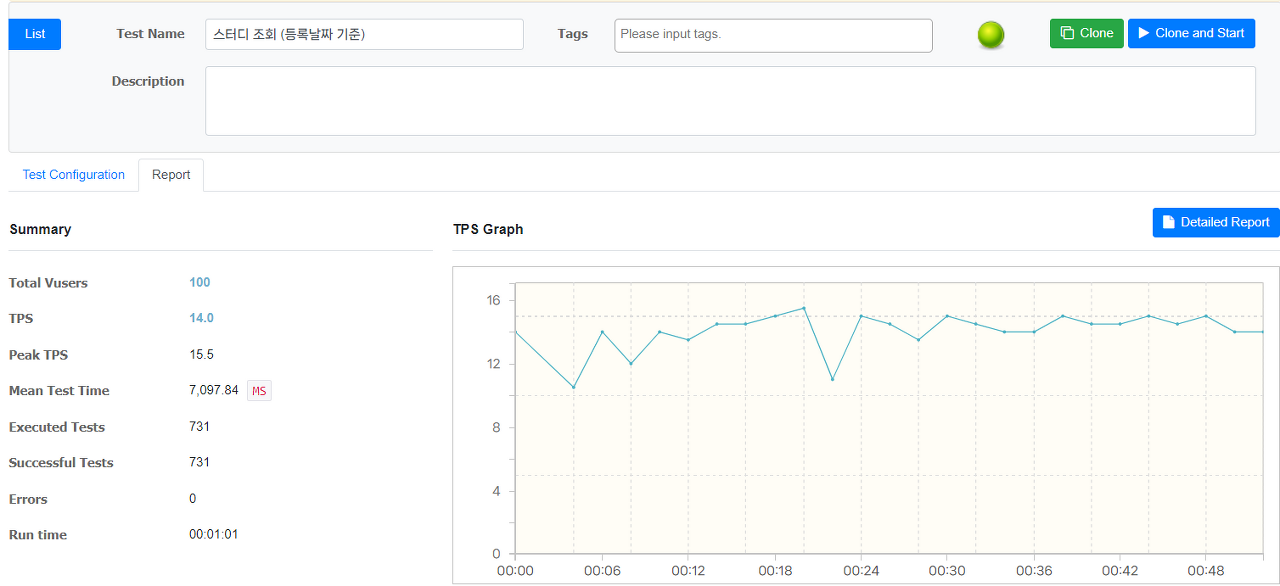




- 여전히 만족스럽지는 못한 응답 성능이지만 그래도 이전의 부하 테스트 결과보다는 Success도 많아졌고 Failed는 전부 없어진 것을 확인할 수 있다
Count Query에 대한 고민
현재 메인 페이지에서는 무한 스크롤을 통해서 스터디를 제공하고 있고 응답 스펙은 다음과 같다
public record StudyPagingResponse(
List<StudyPreview> studies,
boolean hasNext
) {
}
public Slice<StudyPreview> fetchStudyByCategory(
final SearchByCategoryCondition condition,
final Pageable pageable
) {
final List<StudyPreview> result = projectionStudyPreview(
condition.sort(),
pageable,
Arrays.asList(
studyLocationProvinceEq(condition.province()),
studyLocationCityEq(condition.city()),
studyTypeEq(condition.type()),
studyCategoryEq(condition.category()),
studyIsNotTerminated()
)
);
final Long totalCount = query
.select(study.id.count())
.from(study)
.where(
studyLocationProvinceEq(condition.province()),
studyLocationCityEq(condition.city()),
studyTypeEq(condition.type()),
studyCategoryEq(condition.category()),
studyIsNotTerminated()
)
.fetchOne();
return new SliceImpl<>(
result,
pageable,
hasNext(pageable, result.size(), totalCount)
);
}
private boolean hasNext(
final Pageable pageable,
final int contentSize,
final Long totalCount
) {
if (contentSize == pageable.getPageSize()) {
return (long) contentSize * (pageable.getPageNumber() + 1) != totalCount;
}
return false;
}
무한 스크롤 Slice 구조에서 Count Query가 필요할까?
결론은 무한 스크롤 Slice 구조에서 Count Query는 필요 없다
- Pageable’s limit + offset을 통해서 결과 집합 쿼리
- 여기서 핵심은 limit을 조회하려는 size + 1로 적용하기
- 이후 1)에서 조회한 결과 집합(result)과 Pageable’s PageSize를 비교해서 hasNext 판단
- result.size() > pageable.getPageSize() → hasNext true
public Slice<StudyPreview> fetchStudyByCategory(
final SearchByCategoryCondition condition,
final Pageable pageable
) {
final List<StudyPreview> result = projectionStudyPreview(
condition.sort(),
pageable,
Arrays.asList(
studyLocationProvinceEq(condition.province()),
studyLocationCityEq(condition.city()),
studyTypeEq(condition.type()),
studyCategoryEq(condition.category()),
studyIsNotTerminated()
)
);
return new SliceImpl<>(
result.stream().limit(pageable.getPageSize()).toList(),
pageable,
result.size() > pageable.getPageSize()
);
}
private List<StudyPreview> projectionStudyPreview(
final SearchSortType sortType,
final Pageable pageable,
final List<BooleanExpression> whereConditions
) {
return switch (sortType) {
case DATE -> projectionByDate(pageable, whereConditions);
case FAVORITE -> projectionByFavoriteCount(pageable, whereConditions);
default -> projectionByReviewCount(pageable, whereConditions);
};
}
private List<StudyPreview> projectionByDate(
final Pageable pageable,
final List<BooleanExpression> whereConditions
) {
final List<StudyPreview> result = query
.select(studyPreviewProjection())
.from(study)
.where(whereConditions.toArray(Predicate[]::new))
.orderBy(study.id.desc())
.offset(pageable.getOffset())
.limit(pageable.getPageSize() + 1)
.fetch();
if (result.isEmpty()) {
return List.of();
}
final List<Long> studyIds = result.stream()
.map(StudyPreview::getId)
.toList();
applyStudyHashtags(result, studyIds);
applyLikeMarkingMembers(result, studyIds);
return result;
}
...



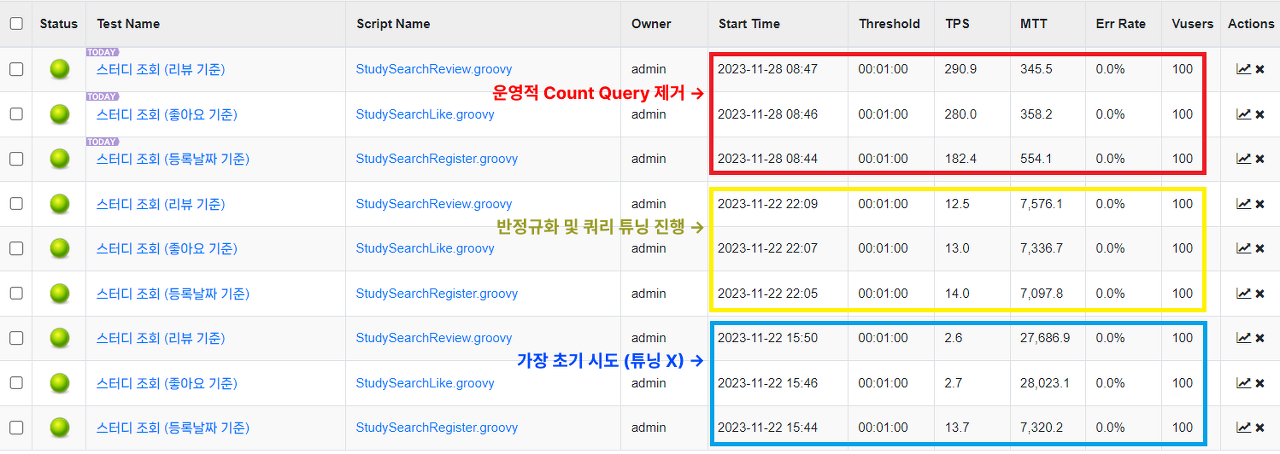
- 등록날짜 기준 쿼리는 조건에 가장 적합한 인덱스가 아닌 PK Index가 적용되었다
- 이 부분은 QueryHint를 통해서 TPS를 더욱 개선할 수 있을거라고 판단된다