

문제 상황
[Spring] 부하 분산 & 서버 가용성을 위한 로드밸런싱
개요 [Spring] 테이블 조인 + 그룹 함수를 통한 정렬 쿼리 튜닝기 (with nGrinder 부하테스트) 개요 GitHub - sjiwon/study-with-me-be: 여기서 구해볼래? Backend Repository (Refactoring) 여기서 구해볼래? Backend Repository
sjiwon-dev.tistory.com
SPOF 구조를 해결하고 부하 분산, 가용성, 응답 최적화, ..등을 위해서 WAS Scale Out을 진행하였다
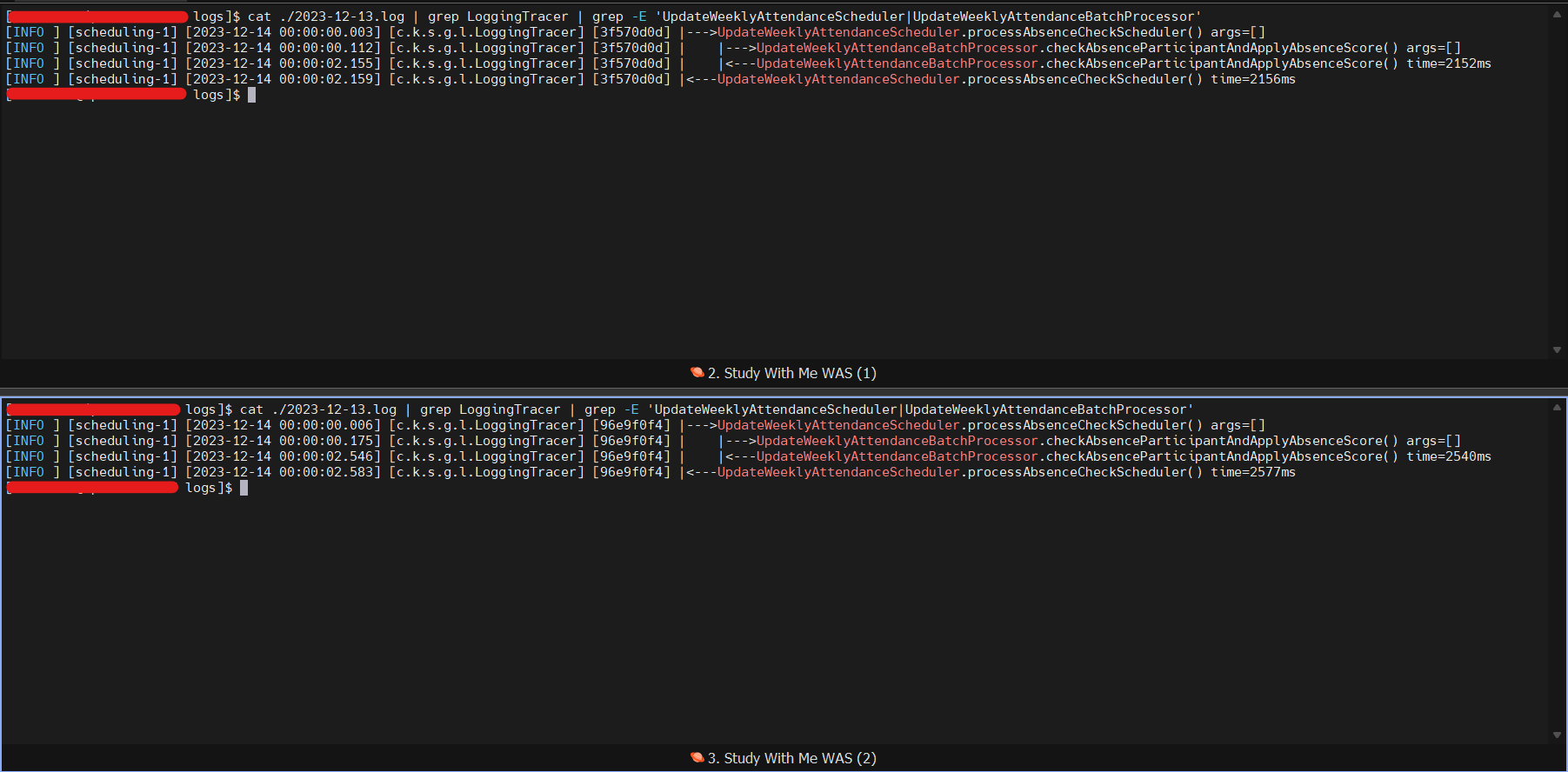
하지만 서버 로그를 살펴보다가 문제가 하나 발생한것을 파악했다
@Component
@RequiredArgsConstructor
public class UpdateWeeklyAttendanceScheduler {
private final UpdateWeeklyAttendanceBatchProcessor updateWeeklyAttendanceBatchProcessor;
@Scheduled(cron = "0 0 0 * * *", zone = "Asia/Seoul")
public void processAbsenceCheckScheduler() {
updateWeeklyAttendanceBatchProcessor.checkAbsenceParticipantAndApplyAbsenceScore();
}
}
@Slf4j
@Component
@RequiredArgsConstructor
public class UpdateWeeklyAttendanceBatchProcessor {
private final StudyWeeklyMetadataRepository studyWeeklyMetadataRepository;
private final StudyAttendanceRepository studyAttendanceRepository;
private final MemberRepository memberRepository;
@StudyWithMeWritableTransactional
public void checkAbsenceParticipantAndApplyAbsenceScore() {
final LocalDateTime now = LocalDateTime.now();
final List<StudyAttendance> nonAttendances = studyAttendanceRepository.findNonAttendanceInformation();
final List<AutoAttendanceAndFinishedWeekly> targetWeekly = studyWeeklyMetadataRepository.findAutoAttendanceAndFinishedWeekly(now.minusDays(2), now);
log.info("결석 처리 대상 Weekly -> {}", targetWeekly); // 처리 시간을 고려해서 [now-2..now]를 target으로 선정
targetWeekly.forEach(week -> {
final Long studyId = week.studyId();
final int specificWeek = week.week();
final Set<Long> participantIds = extractNonAttendanceParticipantIds(nonAttendances, studyId, specificWeek);
if (hasCandidates(participantIds)) {
log.info("결석 처리 정보 -> studyId = {}, weekly = {}, candidates = {}", studyId, specificWeek, participantIds);
studyAttendanceRepository.updateParticipantStatus(studyId, specificWeek, participantIds, ABSENCE);
memberRepository.applyScoreToAbsenceParticipant(participantIds);
}
});
}
private Set<Long> extractNonAttendanceParticipantIds(
final List<StudyAttendance> nonAttendances,
final Long studyId,
final int week
) {
return nonAttendances.stream()
.filter(nonAttendance -> nonAttendance.getStudy().getId().equals(studyId) && nonAttendance.getWeek() == week)
.map(studyAttendance -> studyAttendance.getParticipant().getId())
.collect(Collectors.toSet());
}
private boolean hasCandidates(final Set<Long> participantIds) {
return !CollectionUtils.isEmpty(participantIds);
}
}매일 밤 12시마다 자동 출석 대상인 Weekly에 대해서 결석 대상 참여자들에 대한 결석 처리 스케줄링이 진행된다
하지만 여기서 Scale Out으로 인해 이 스케줄링 로직이 중복되어서 실행되고 있다
이를 어떻게 제어해서 중복 실행을 방지할 수 있을까?
With Redis (setnx)
위와 같은 중복 실행을 제어하기 위해서는 다음과 같은 선행 로직이 필요할 것이다
- N대의 서버가 바라볼 수 있는 공용 공간에 대해서 중복 실행 제어를 관리
- 해당 공간을 통해서 스케줄링 로직 진입 전에 체크
가장 중요한 것은 해당 공용 공간에 대해서 여러 요청이 동시에 들어갔을 때 이 요청을 순차적으로 처리해줘야 한다
- 실행되었는지 확인하는 로직이 동시에 들어가도 순차적으로 체크
이러한 요구조건에 가장 적합한 도구는 Redis - setnx 명령어라고 판단된다
→ Set the string value of a key only when the key doesn’t exist.
Redis는 Client’s Command를 싱글 쓰레드로 처리하기 때문에 동시에 들어오는 명령어들을 순차적으로 처리할 수 있고 setnx 또한 Atomic을 보장하는 명령어이다
- 따라서 Redis’s setnx를 통해서 중복 실행을 제어하는게 효과적이라고 판단된다
- 물론 자바에서도 Atomic{…} 시리즈의 Atomic 연산 클래스가 존재하고 AtomicBoolean을 통해서 제어할 수도 있겠지만 이는 단일 인스턴스상에서 보장되는 동시성이므로 결국 중복 실행 문제가 다시 발생할 것이고 고려 X
@Component
@RequiredArgsConstructor
public class UpdateWeeklyAttendanceScheduler {
private final StringRedisTemplate redisTemplate;
private final UpdateWeeklyAttendanceBatchProcessor updateWeeklyAttendanceBatchProcessor;
@Scheduled(cron = "0 0 0 * * *", zone = "Asia/Seoul")
public void processAbsenceCheckScheduler() {
if (canExecute()) {
updateWeeklyAttendanceBatchProcessor.checkAbsenceParticipantAndApplyAbsenceScore();
}
}
private boolean canExecute() {
return Boolean.TRUE.equals(redisTemplate.opsForValue().setIfAbsent("scheduling", "on", Duration.ofMinutes(5)));
}
}
- Redis setnx를 통해서 분산 환경에서의 스케줄링 중복 실행을 제어할 수 있게 되었다
ShedLock?
관련된 토픽을 찾아보다가 ShedLock이란 존재도 알게되었고 대부분의 아티클에서 분산 환경에서의 스케줄링 중복 실행을 방지하기 위해서 ShedLock을 활용하고 있다
GitHub - lukas-krecan/ShedLock: Distributed lock for your scheduled tasks
Distributed lock for your scheduled tasks. Contribute to lukas-krecan/ShedLock development by creating an account on GitHub.
github.com
DB나 분산 저장소에 메타적인 Lock을 일정 시간동안 적용함으로써 여러 서버가 존재하더라도 단 하나의 서버에서만 ShedLock을 걸고 스케줄링 로직으로 들어가는 아키텍처인듯하다
ShedLock이라는 좋은 방법도 있지만 현재 스케줄링 로직이 그렇게 복잡하고 하드한 로직이 아니고 매일 밤 12시 정각에 단 1번 3 ~ 5s 동안 돌아가기 때문에 Redis setnx로도 충분히 제어 가능하다고 판단하였고 그에 따라서 Redis를 활용한 제어 방식을 선택하였다