

DB Connection
Web Application Server(WAS) ↔ DB Server간에 네트워크 통신을 위해서는 TCP/IP Connection을 맺어야 한다
- WAS에서는 적절한 DB Driver를 통해서 DBMS에 Connection 요청을 진행한다
- DB Driver는 WAS ↔ DBMS 사이에서 데이터를 주고 받는 통로 역할
- Connection 요청을 처리할 DB Driver는 DBMS와 TCP/IP Connection을 맺는다
- 3-Way Handshake (SYN / ACK-SYN/ ACK)
- TCP/IP Connection을 맺은 후 DB Driver는 인증 정보를 DBMS에 전달한다
- DBMS는 Client에 대한 인증을 진행하고 Connection 요청에 대한 DB Session을 생성한다
- 이후 DBMS는 DB Driver에게 Connection & Session 맺음에 대한 응답을 제공한다
- 응답을 받은 DB Driver는 DB Connection을 생성해서 WAS에 제공한다
이 과정을 Connection이 필요할때마다 진행하면 어떻게 될까?
MySQL :: MySQL 8.0 Reference Manual :: 8.2.5.1 Optimizing INSERT Statements
8.2.5.1 Optimizing INSERT Statements To optimize insert speed, combine many small operations into a single large operation. Ideally, you make a single connection, send the data for many new rows at once, and delay all index updates and consistency checkin
dev.mysql.com
간단한 예시로 MySQL에서 Insert를 진행할 때 과정별로 리소스 소모에 대한 비율은 다음과 같다

물론 상대적인 비율이긴 하지만 DB Connection을 맺는 시간이 상대적으로 가장 오래 걸리는 것을 확인할 수 있다
따라서 요청에 따라 매번 DB Connection을 생성하고 반납하는 절차는 그렇게 효율적이지는 않아보인다
DBCP (Database ConnectionPool)
[Java] ThreadPool
ThreadPool 어떤 요청이 들어왔을 때 해당 요청을 처리하기 위해서 쓰레드를 사용하는 가장 Naive한 방법은 요청마다 쓰레드를 생성하고 할당하는 것이다 쓰레드가 필요한 시점에 생성 요청 OS가 해
sjiwon-dev.tistory.com
이전 포스팅에서 알아봤듯이 자바에서 Thread를 효율적으로 관리하기 위해서 ThreadPool이라는 공간을 제공한다
- 매번 Thread를 생성하고 반납하는 절차가 불필요한 리소스를 낭비하기 때문에 이를 개선하기 위해서 ThreadPool을 도입
DB Connection도 비슷한 논리로 매번 DB Connection을 생성하고 반납하는 절차가 불필요한 리소스 낭비를 하기 때문에 DBCP라는 개념이 등장한 것이다
DBCP도 ThreadPool과 마찬가지로 일정 개수의 DB Connection을 DBCP에서 관리함으로써 매번 생성하고 반납하는 불필요한 리소스를 줄인다
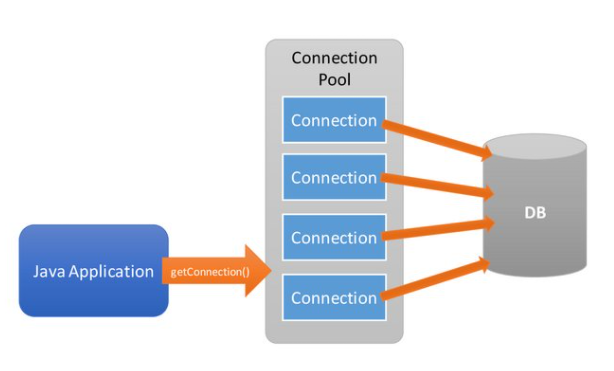
DBCP의 효율성
CREATE DATABASE dbcp;
CREATE TABLE members
(
id BIGINT AUTO_INCREMENT,
name VARCHAR(25),
password VARCHAR(25),
PRIMARY KEY (id)
) ENGINE = InnoDB;100번의 Insert를 하는 로직에서 매번 DB Connection을 생성하는것과 리스트를 활용한 심플한 DBCP를 활용하는것과 어떤 차이가 있을지 살펴보자
private const val URL = "jdbc:mysql://localhost:3306/dbcp"
private const val USERNAME = "root"
private const val PASSWORD = "1234"
class AlwaysNew {
fun insert() {
DriverManager.getConnection(URL, USERNAME, PASSWORD).use {
it.prepareStatement("INSERT INTO members(name, password) VALUES(?, ?)").apply {
setString(1, "Member")
setString(2, "1234")
executeUpdate()
}
}
}
}
class Keep {
private val pool: List<Connection> = (1..10).map { DriverManager.getConnection(URL, USERNAME, PASSWORD) }
private var pointer = 0
fun insert() {
val connection = pool[pointer % pool.size]
connection.prepareStatement("INSERT INTO members(name, password) VALUES(?, ?)").apply {
setString(1, "Member")
setString(2, "1234")
executeUpdate()
}
pointer++
}
}
fun main() {
val alwaysNew = AlwaysNew()
execute("매번 생성 (DBCP X)") { repeat(100) { alwaysNew.insert() } }
val keep = Keep()
execute("미리 생성하고 재사용 (DBCP O)") { repeat(100) { keep.insert() } }
}
private fun execute(
title: String,
logic: () -> Unit,
) {
println("## $title ##")
val start = System.currentTimeMillis()
logic()
val end = System.currentTimeMillis()
println("Execute = ${end - start}ms\n")
}
코드레벨에서 List를 활용해서 간단한 ConnectionPool을 만들었는데도 매번 생성하고 반납하는 메커니즘보다 훨씬 성능이 좋은것을 확인할 수 있다
이를 통해서 매번 DB Connection을 생성하고 반납하는 절차는 굉장히 비효율적으로 리소스를 활용하는 것을 파악할 수 있고 DBCP를 통해서 효율적으로 관리해야 한다
Connection은 무조건 많을수록 좋을까?
그러면 이제 고민해야할 부분은 DBCP에 어느정도의 DB Connection을 관리해야 좋을까이다
과연 무조건 최대한 많이 DB Connection을 늘릴 수록 좋을까?
1) 리소스 사용
DBMS든 WAS든 서버이다
그렇기 때문에 서버에서 관리하는 자원의 수가 많으면 많을수록 부담이 가게 된다
DBMS에서 DB Connection을 점차 많이 관리하면 할수록 메모리/CPU를 더욱 많이 사용하게 되고 이러한 부분이 부담이 될 수 있는 것이다
그리고 WAS로 들어오는 요청을 담당하는 주체는 WAS Thread이고 진행하는 로직에서 DB와의 I/O가 필요하면 그 시점에 DB Connection이 필요하다
따라서 ThreadPool은 고려하지 않고 무작정 DB Connection만 늘리게 되면 오히려 DBCP에서 Idle상태로 존재하는 Connection만 많아지고 쓸데없는 메모리만 차지하게 되는 것이다
2) Thread Context Switching
그렇다고 해서 WAS ThreadPool의 Thread도 무작정 늘리게 된다면 문제가 될 수 있다
Thread가 많아질수록 Thread간에 Context Switching 비용이 증가하게 된다
이로 인해 CPU는 실질적인 비즈니스 로직 연산에 힘을 쏟는것이 아니라 오히려 Context Switching에 시간을 더 쏟게 되고 이는 전반적인 시스템 성능 저하를 유발할 수 있다
3) Blocking I/O
Connection을 늘리는것과는 약간 별개로 R2DBC를 사용하지 않는 이상 기본적으로 DB에 대한 I/O 연산은 Blocking I/O이다
그러면 결국 로직을 처리하던 WAS Thread는 DB에 대한 Blocking I/O를 진행하는 시점 동안은 Blocking되고 다른 작업을 수행할 수 없게 된다
따라서 이러한 Thread Blocking 또한 너무 오랫동안 지속되면 전체 시스템의 효율성이 떨어질 수 있다
결론적으로, 무작정 많은 것이 좋은게 아니라 효율적으로 여러 가지 성능/부하 테스트를 통해 현재 프로젝트에 적절한 튜닝을 하는것이 중요하다
HikariCP
GitHub - brettwooldridge/HikariCP: 光 HikariCP・A solid, high-performance, JDBC connection pool at last.
光 HikariCP・A solid, high-performance, JDBC connection pool at last. - brettwooldridge/HikariCP
github.com
A solid, high-performance, JDBC connection pool at last.
Project에서 설명하고 있듯이 HikariCP는 ConnectionPool의 한 종류이다
- Apache Common DBCP, Tomcat DBCP, Oracle DBCP, ..등 많은 종류의 DBCP가 존재한다
- Spring Boot 2.0부터는 HikariCP를 Default DBCP로 활용한다
본 포스팅에서는 HikariCP의 주요 컴포넌트에 대한 간략한 설명만 제공할 예정이다
- HikariCP가 Connection을 다루는 과정은 이후 포스팅에서 자세히 설명
ConcurrentBag
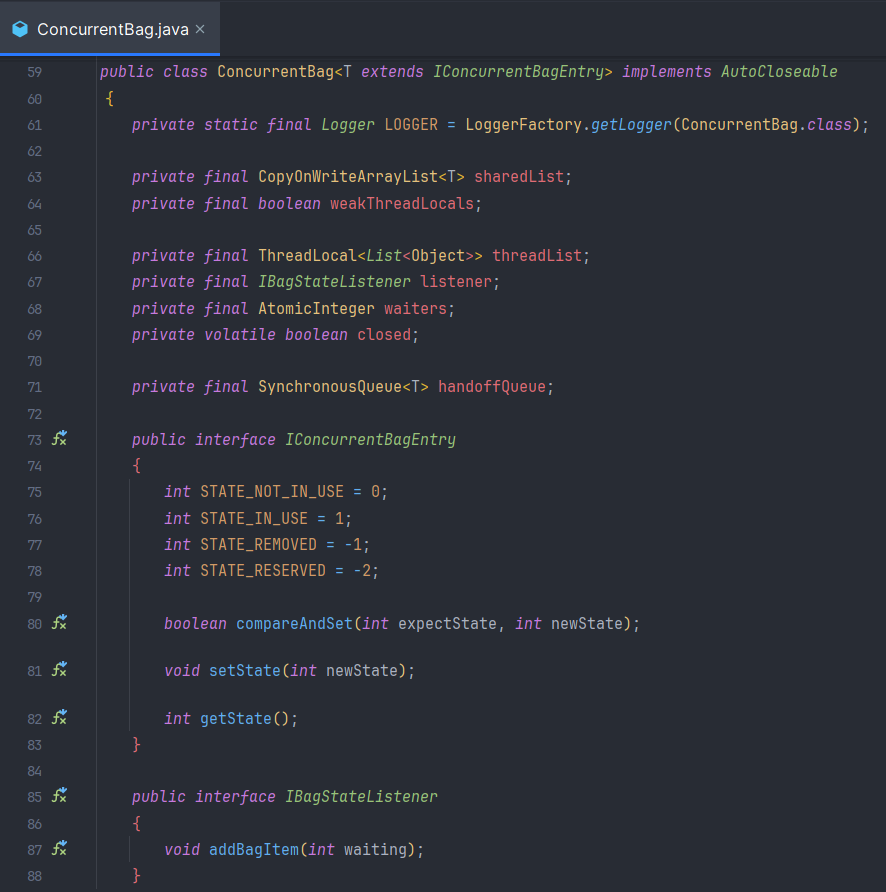
This is a specialized concurrent bag that achieves superior performance to LinkedBlockingQueue and LinkedTransferQueue for the purposes of a connection pool.
It uses ThreadLocal storage when possible to avoid locks, but resorts to scanning a common collection if there are no available items in the ThreadLocal list.
Not-in-use items in the ThreadLocal lists can be "stolen" when the borrowing thread has none of its own. It is a "lock-less" implementation using a specialized AbstractQueuedLongSynchronizer to manage cross-thread signaling.
Note that items that are "borrowed" from the bag are not actually removed from any collection, so garbage collection will not occur even if the reference is abandoned. Thus care must be taken to "requite" borrowed objects otherwise a memory leak will result. Only the "remove" method can completely remove an object from the bag.

ConcurrentBag은 PoolEntry를 Wrapping해서 관리하는 컴포넌트라고 생각하면 된다
- PoolEntry는 실질적으로 DB Connection을 Wrapping해서 관리하고 추가적인 메타 정보를 트래킹하는 컴포넌트
ConcurrentBag은 HikariCP에서 핵심적인 메커니즘을 담당하는 3가지 저장소가 존재한다
1) SharedList → CopyOnWriteArrayList
HikariCP에서 사용 가능한 모든 Connection을 관리하는 공유 저장소
- 새로 생성된 DB Connection은 sharedList에 등록된다
- 여러 Thread에서 동시에 접근할 수 있기 때문에 동시성 문제를 고려해서 CopyOnWriteArrayList로 적용되어 있다
2) threadList → ThreadLocal<List>
특정 Thread가 사용한 DB Connection을 추적하기 위한 Thread별 Connection 관리 저장소
3) handoffQueue → SynchronousQueue
Idle Connection 요청 시 현재는 없고 그에 따라서 주기적으로 Connection을 얻기 위해서 Polling하는 Queue
- threadList, sharedList 다 찾아봐도 Idle Connection이 없는 경우 handoffQueue에 대한 지속적인 Polling을 통해서 새로운 Connection이 생겼는지 확인한다 (Timeout 동안)
추후 포스팅에서 알아보겠지만 ConcurrentBag#borrow()를 통해서 DB Connection을 얻는 과정이 진행된다
PoolEntry

Connection + Connection에 대한 추가적인 메타 정보를 관리하는 컴포넌트이다
- 마지막 Access
- 마지막 Borrow
- Connection state
- isReadOnly
- isAutoCommit
- ...
이러한 정보들을 모두 종합해서 HikariPool에서 해당 Connection을 사용할지 말지 결정한다

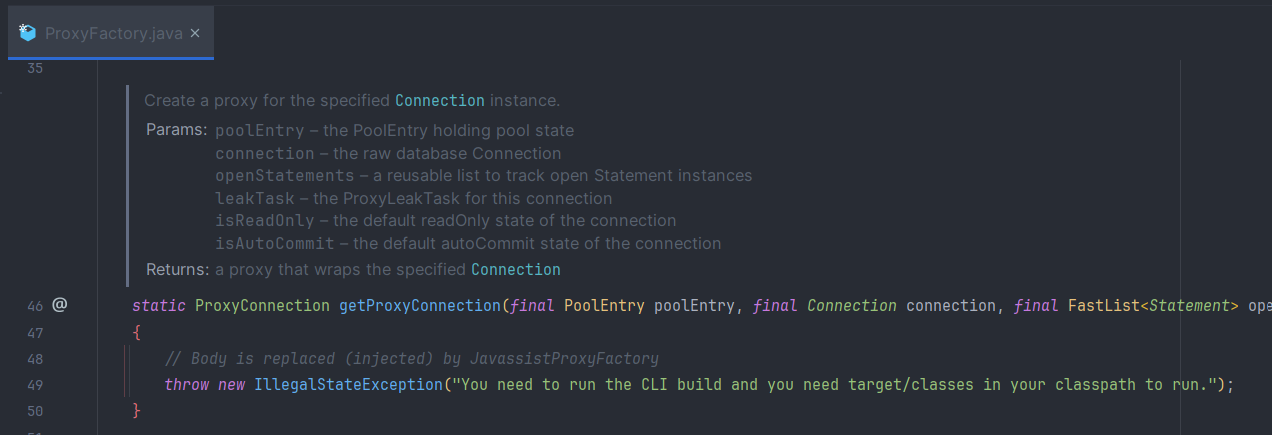
PoolEntry에서는 Connection을 한번 더 Proxy로 Wrapping한 HikariProxyConnection을 응답한다
HouseKeeper
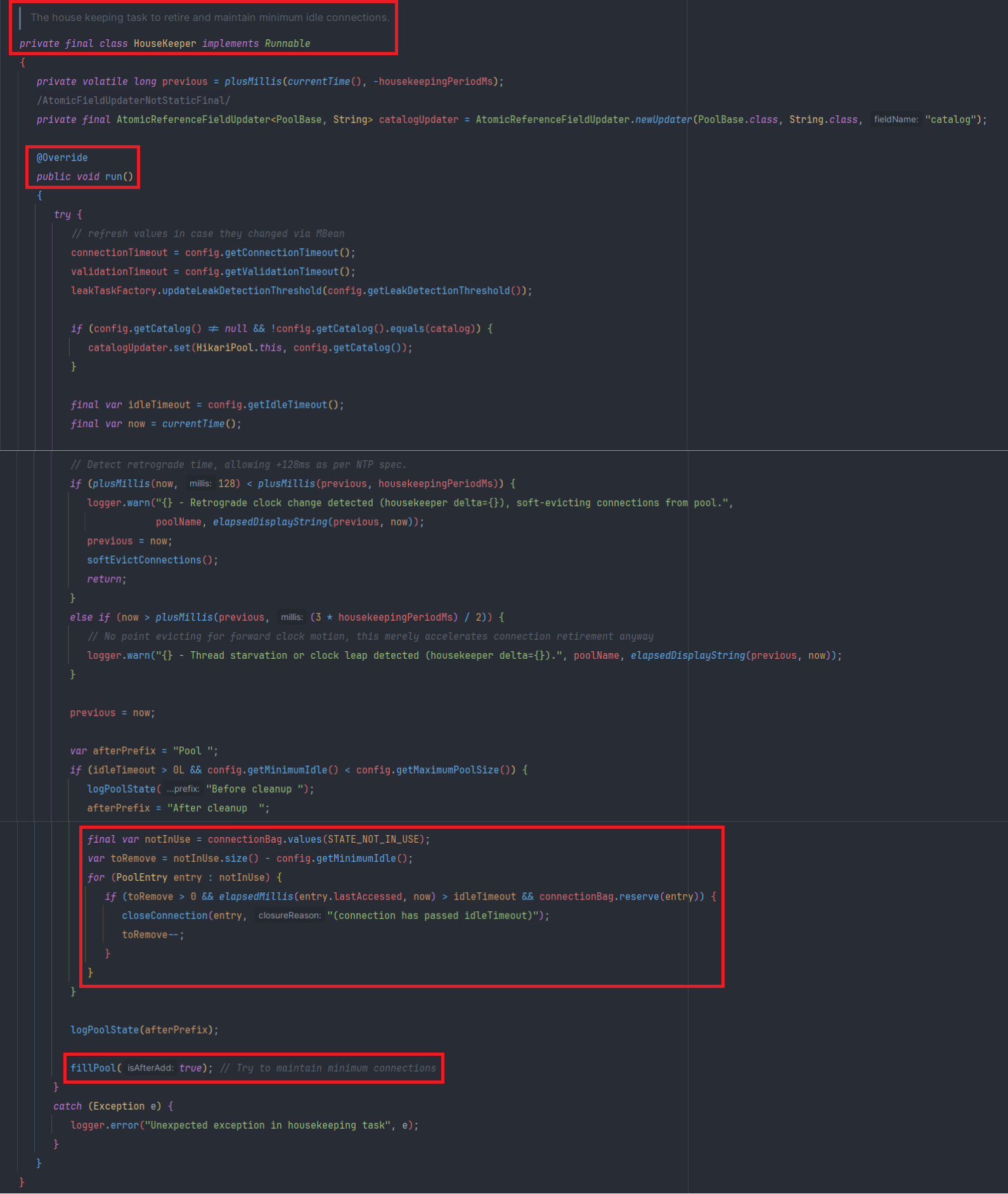
HouseKeeper는 주기적으로 ConnectionPool을 관리하는 역할을 하는 Thread이다
- HikariPool에서 ScheduledExecutorService에 의해 관리되고 주기적으로 실행
- 유효하지 않거나 timeout이 만료된 Connection 지워주기
- minimum connection을 유지하기 위해서 ConnectionPool 채우기 → fillPool()

- fillPool(true)를 통해서 HouseKeeper는 minimum connection을 유지한다